Readiness Frameworks Are Quietly Deciding the Enterprise AI Platform Wars
An in-depth analysis of the emerging “CIO playbook” for enterprise AI platforms: why five-domain readiness scorecards and parallel, six-week POCs are becoming the real battleground where SiliconFlow, Kore.ai, IBM watsonx, Google Vertex AI, Microsoft Copilot Studio, Hugging Face, and others rise or fall.
The Case: A CIO Turns Platform Chaos into a Controlled Experiment
In 2026, the CIO of a global financial services firm was under pressure to “pick an AI platform” before the next board meeting. The vendor landscape was noisy: SiliconFlow promising high-throughput managed inference, Kore.ai pushing agentic CX automation, IBM watsonx selling governance-first hybrids, Google Vertex AI and Microsoft Copilot Studio touting tight ecosystem integration, plus open options like Hugging Face Enterprise.
Instead of choosing by brand gravity, the CIO’s team built a structured evaluation engine. First came a two-week readiness assessment across five domains: data, infrastructure, talent, governance, and budget. They scored each from 1-10, weighted (Data 30%, Infra 25%, Talent 20%, Governance 15%, Budget 10%), and agreed on a “go” threshold of 7/10 before committing to any platform.
The assessment surfaced familiar issues. Only ~65% of key data had acceptable quality; most datasets were weeks out of date. GPU queues were long, and the firm had just two engineers with modern MLOps experience. Governance scored better thanks to existing SOC2 controls, but AI-specific policies were thin. Overall readiness: 6.4/10. Rather than pause, they used the findings to narrow scope. They ring-fenced one high-value use case-customer-support augmentation-and funded a short, focused remediation sprint to push data completeness past 90% and freshness under seven days.
Then came the real contest: three parallel six-week POCs across SiliconFlow, Kore.ai, and Vertex AI, with a small IBM watsonx pilot for regulated workflows. Each POC had identical KPIs: latency (<1s p95), task accuracy (>85% on a curated test set), cost (<$1 per query all-in), and a target modeled ROI of roughly 3x within six months. Budget was capped at $40K, spanning inference spend, small data-cleanup efforts, and vendor support.
By week six, the firm hadn’t just picked Kore.ai for frontline automation plus SiliconFlow for managed inference; it had built a reusable evaluation pipeline. That same five-domain readiness scorecard and benchmarking harness became the starting point for every new AI initiative, turning a one-off platform decision into a standing capability.
The Pattern: Enterprise AI Decisions Are Being Outsourced to Readiness Engines
Zooming out from this single firm, a broader pattern is emerging across large enterprises. As AI platforms proliferate and models converge in raw capability, CIOs are quietly shifting decision power away from one-off RFPs and toward institutionalized “readiness engines” and standardized POC frameworks.
At the surface, many organizations describe the same components as the CIO in the case above: a two-to-four-week readiness assessment, a five-domain scorecard (data, infrastructure, talent, governance, budget), and a multi-vendor, six-week POC. Underneath, something more structural is happening.
First, the unit of decision has changed. Instead of, “Which platform should we buy?”, the operative question becomes, “Given our current readiness profile, what kinds of platforms and architectures are compatible with us right now?” A data score below 7/10 nudges the organization toward platforms with strong RAG tooling and federated connectors. Weak talent scores bias toward low-code agent builders like Copilot Studio or Kore.ai. Governance gaps make watsonx or Vertex AI’s policy frameworks more attractive. The readiness engine narrows the plausible subset of platforms before commercial conversations even begin.
Second, platform selection is increasingly treated as an experiment, not a bet. CIOs that once ran linear RFPs now orchestrate parallel POCs with 3-5 vendors, using common test harnesses and highly specific KPIs: tokens per second, context window size, governance features, integration coverage, and total cost of ownership. Typical targets have quietly standardized: data completeness >90%, data freshness under seven days, inference costs in the $0.50-$2 per million tokens range, storage around $0.02 per GB per month, and a modeled 3x ROI within six months.

Third, the real asset is no longer the platform alone, but the evaluation pipeline itself. Enterprises build internal benchmark datasets, latency tests, and governance checklists that can be re-run whenever a new model or vendor appears. Once this machinery exists, platform choice becomes a repeatable output of an internal process rather than a hero decision by one visionary executive.
Finally, these engines redistribute power inside the organization. Platform decisions move from isolated innovation labs to cross-functional committees where IT, security, data, legal, and business units jointly define weighted criteria: scalability and performance (~30%), compliance and governance (~25%), integration (~20%), TCO (~15%), and innovation features like multi-model and agentic capabilities (~10%). The decision is still political, but the arguments are anchored in standardized scores and POC results rather than slideware.
In effect, enterprises are building an internal “market” where AI platforms compete under controlled conditions. The readiness framework sets who is allowed into the market; the POC harness sets the rules of competition. Vendors still sell to CIOs, but, structurally, they are now selling into these evaluation engines.
The Mechanics: Incentives, Constraints, and Feedback Loops in the New AI Decision Stack
Why are readiness assessments and structured POCs becoming the de facto arbiters of AI platform choice? The answer lies in how they balance competing incentives under hard constraints, then turn results into a repeating feedback loop.
Incentives and risk hedging. CIOs need visible progress and defensible risk posture. Business units want automation yesterday. CISOs and compliance teams worry about data leakage, bias, and opaque models. Data teams fear overcommitting before data quality catches up. Vendors want lock-in. The five-domain readiness scorecard functions as a truce: it surfaces weaknesses early, ties them to quantified scores, and frames risk reduction as an explicit precondition for scale.
By agreeing that, for example, data and infrastructure scores must exceed 7/10 before expanding beyond a pilot, stakeholders can align around investing in foundations first: building connectors, cleaning data, tightening IAM, or upgrading monitoring. The scorecard is not only diagnostic; it is a political coordination device.
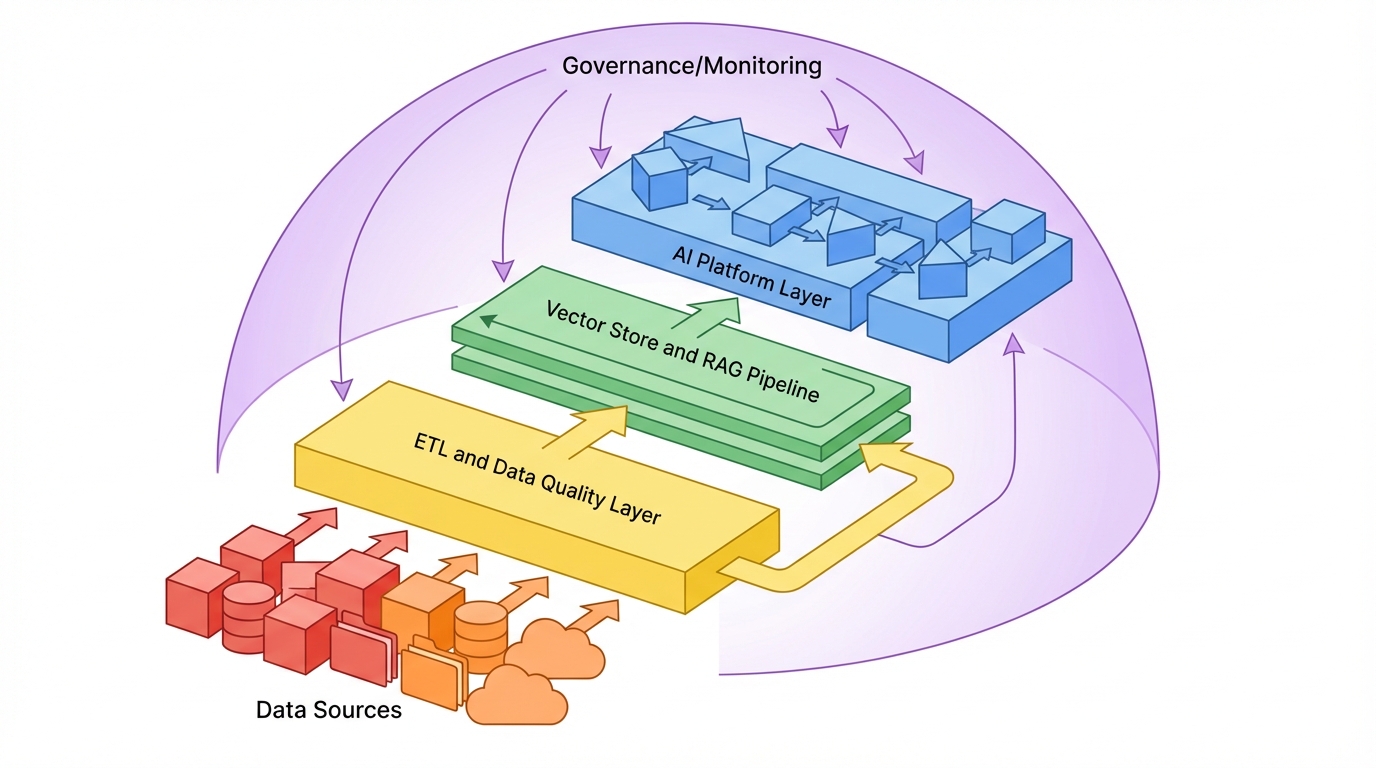
Technical constraints and platform filtering. Concrete metrics give the framework teeth. Enterprises commonly anchor on >90% data completeness and sub-seven-day freshness for the datasets feeding initial AI use cases. If existing warehouses cannot meet this, they lean on RAG patterns that can work across partially structured repositories and content stores. That, in turn, privileges platforms with robust RAG tooling and federated connectors-which is why integrations (often 500+ SaaS connectors) now appear so prominently in vendor marketing.
On the infrastructure side, GPU scarcity and latency targets force trade-offs. If an organization cannot reliably secure accelerators, platforms that provide managed inference (SiliconFlow, Bedrock-style services, Hugging Face endpoints) gain an edge. Latency targets, such as <500ms p95 for interactive use, push enterprises toward quantization, caching, and hybrid architectures where large models are paired with smaller, faster ones. Platforms that expose these knobs cleanly or automate them win more points in the performance and TCO columns.
Talent, governance, and tool choice. Talent shortages are another structural constraint. Many enterprises have a handful of ML engineers but hundreds of developers and analysts. A readiness score that penalizes gaps in MLOps or prompt engineering naturally redirects selection toward low-code and agentic builders—Kore.ai’s studio, Copilot Studio, or workflow-centric platforms that allow non-specialists to orchestrate agents, tools, and data sources safely.
Governance scores embed regulatory and reputational concerns into the platform contest. Requirements like SOC2, GDPR support, RBAC, audit logs, bias metrics, and explainability dashboards become explicit checklist items in the POC. A platform may outperform on accuracy but still lose if it cannot demonstrate, say, drift detection or per-tenant data isolation. This is why governance-forward offerings like watsonx and Vertex AI’s monitoring stack often stay in the running, even if their raw model zoo looks less glamorous than frontier-model boutiques.
Cost modeling as a forcing function. Before POCs start, many CIO teams now pre-commit to rough economics: inference in the $0.50–$2 per million tokens range, storage around $0.02 per GB per month, and a target of about 3x ROI within six months on any productionized POC. They model TCO across three dimensions—usage-based inference, platform or seat licenses, and adjacent costs like data labeling or integration.
This up-front modeling has two mechanical effects. It caps POC budgets (often $20K–$50K per use case), forcing a focus on 2–3 high-impact workflows, and it creates a uniform yardstick across vendors. A platform that looks cheap on licensing but requires proprietary hardware or dedicated staff will score poorly on effective TCO relative to a slightly pricier API with strong automation.
Feedback loops and institutional learning. The most important mechanical feature is that these frameworks are repeatable. Every POC—successful or not—produces new data: actual latency under load, real hallucination rates, governance incident counts, measured uplift in agent handle time or sales conversion. These outcomes feed back into the readiness model.
For example, a failed POC that stalls due to poor data lineage may lower the organization’s effective “data readiness” score and trigger additional investment in catalogs or observability. A successful experiment using multi-model routing might raise the perceived value of platforms that support easy model swapping and tool orchestration. Over time, the enterprise effectively trains its own internal policy: which combinations of readiness scores, platform characteristics, and use-case types tend to yield 3x ROI within six months.
This creates a flywheel. As the evaluation engine learns, subsequent platform contests become faster and more decisive. Vendors must either fit into the learned patterns—multi-model support, strong governance, reasonable token economics—or accept being screened out early.
The Implications: What Becomes Predictable When Readiness Decides
If this readiness-driven pattern holds, several aspects of the enterprise AI landscape become more predictable.
First, platform differentiation will continue to drift away from raw model quality and toward how tightly a platform aligns with the five readiness domains. Vendors that offer strong connectors, flexible deployment (cloud, hybrid, on-prem), clear governance primitives, and multi-model or agentic capabilities are structurally advantaged. As long as frontier models can be accessed through multiple platforms, CIOs will optimize primarily for integration, control, and economic predictability.
Second, evaluation itself will harden into a standing organizational capability. The kind of six-week, multi-platform POC described in the case will no longer be a special project; it will be the baseline path for any significant AI investment. Board-level AI discussions will increasingly revolve around readiness scores, standardized KPI dashboards, and portfolio-level ROI rather than one-off platform bets.
Third, vendor lock-in pressures will change character. Dominant cloud ecosystems will still exert gravitational pull, but the existence of internal benchmarking harnesses and cross-platform abstractions (OpenAI-compatible APIs, shared orchestration layers, federated data connectors) will make it easier—though never free—to swap or multi-home between platforms. Platforms that lean into this and embrace multi-model interoperability are more likely to survive as strategic partners rather than transient tools.
There is a darker implication, too. The same frameworks that enable disciplined decision-making can calcify into “readiness theater,” where low scores become a convenient excuse for inaction, or where the process bloats into a bureaucratic gate that innovators route around with shadow AI tools. Organizations that treat the scorecard as a living instrument, tuned by POC feedback, will outpace those that freeze it as policy.
For CIOs, the structural message is blunt: the pivotal capability is no longer choosing the perfect AI platform, but designing and running the evaluation machine that will choose, re-choose, and sometimes un-choose platforms over time. Enterprises that invest in that machine—a rigorous five-domain readiness model, reproducible six-week POCs across multiple vendors, and explicit ROI thresholds—will not be insulated from AI risk. But they will be structurally better positioned to turn a chaotic platform market into a managed, renewable advantage.
Leave a Reply