Nvidia’s AI Supercomputers & 6G: The Next Infrastructure War
Two forces are converging to redraw the enterprise technology map: GPU-rich AI supercomputers and the coming wave of 6G networks. The winners won’t simply buy more GPUs or wait for new spectrum-they’ll co-design compute and connectivity to collapse cost, latency, and time-to-market. This is the new infrastructure war, and the next 18-36 months will set trajectories for the 2030s.
Executive Hook: Your cost floor and latency ceiling are about to move
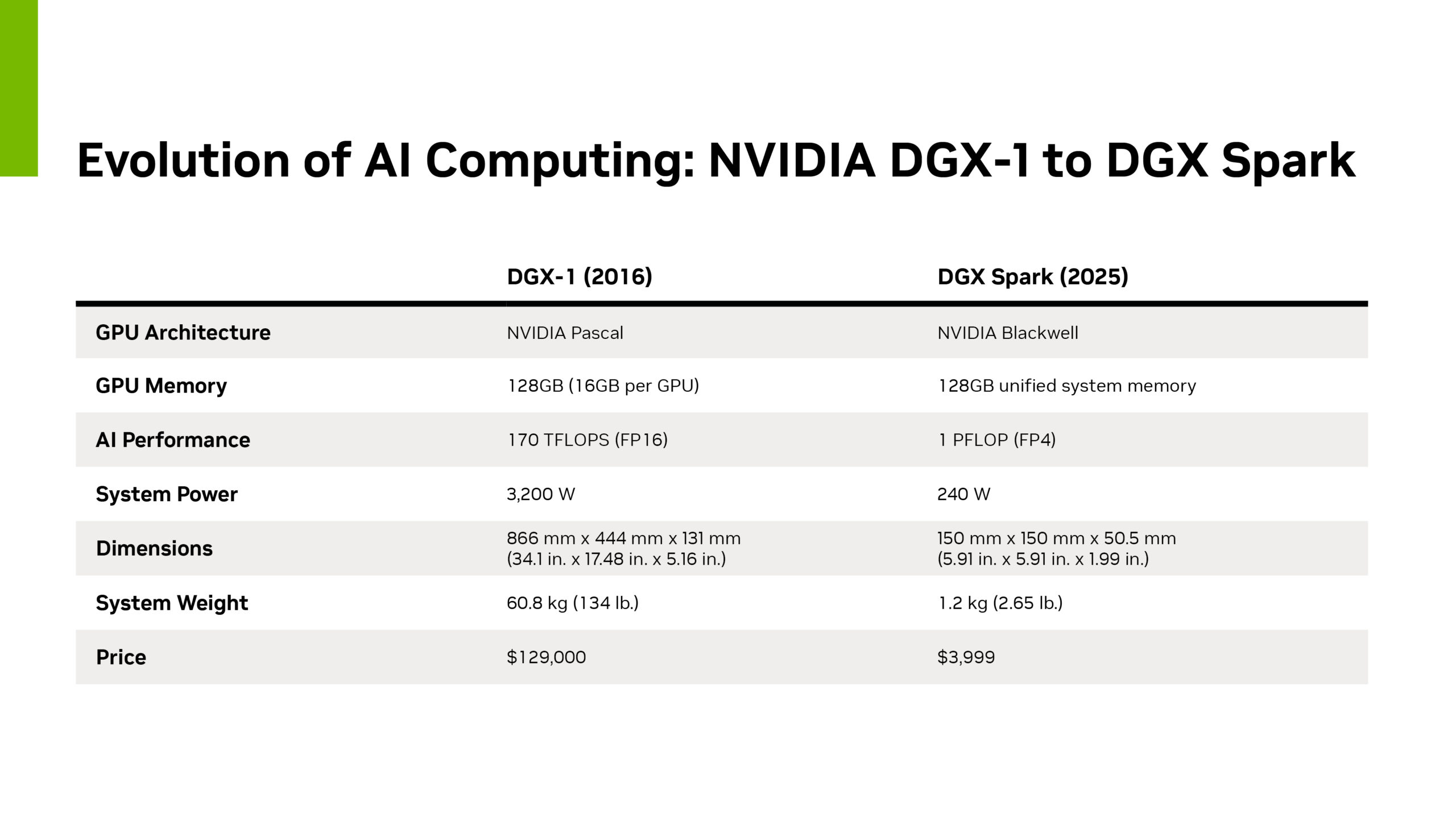
Nvidia’s latest AI systems-DGX-class, Blackwell-era superchips, and dense, liquid-cooled racks-compress months of experimentation into days. In parallel, 6G research promises sub-millisecond links, integrated sensing, and space/terrestrial coverage. Together, they reset the economics of where models are trained, tuned, and served. If you’re not actively planning for a world where model execution lives across data center, regional edge, and on-prem sites—bound by deterministic wireless—you’re giving competitors a compounding advantage.
Industry Context: Why this matters for competitive advantage
Three realities are colliding:
- Compute gravity is shifting. Blackwell-generation systems deliver step-change performance per watt, making on-prem or colo GPU clusters viable for sustained training, fine-tuning, and high-throughput inference—especially where data egress, privacy, or latency dominate economics.
- Networks are becoming AI-native. 5G-Advanced is already pushing RAN automation, network slicing, and edge offload. 6G will add sub-THz options, non-terrestrial networks, joint communication-and-sensing, and tighter time synchronization—turning networks into an active participant in AI workloads.
- Scarcity and power shape strategy. Lead times for high-end GPUs, power availability (30-80 kW per rack for dense GPU), and cooling constraints favor those who move early on facilities, grid contracts, and edge footprints.
Net effect: the enterprise stack is rebalancing. Training will stay hybrid. Fine-tuning and inference will push closer to data. Networks will become programmable fabric that ensures the right workload runs in the right place at the right time—profitably.
Core Insight: Co-design compute and connectivity as one system
Most roadmaps treat GPUs and networks as separate buying cycles. That’s a mistake. The real advantage comes from a compute-network flywheel: local AI supercomputers collapse iteration time; deterministic wireless collapses decision latency; together they enable products competitors can’t ship on public cloud alone.
- Where the cloud still wins: elastic bursts, global routing, and rapid experimentation before utilization stabilizes.
- Where on-prem GPU wins: steady-state fine-tuning/inference on proprietary data, predictable volumes, heavy egress costs, or regulated workloads.
- Where 6G will matter: control loops and perception workloads (robotics, industrial automation, teleoperation, spatial computing) where sub-10 ms end-to-end latency and sensing-integrated links change what’s possible.
In practice, the strongest ROI we see comes from a tiered architecture: reserve cloud for burst training and global distribution; run fine-tuning and bulk inference on DGX-class clusters in regional colos; push mission-critical inference to on-prem edge with private cellular today and 6G-capable designs tomorrow.
Common Misconceptions: What most companies get wrong
- “More GPUs = more value.” Not unless you hit 60-80% sustained utilization and align data pipelines, MLOps, and power/cooling. Idle GPUs destroy TCO.
- “6G will fix our latency problems soon.” Commercial 6G is a 2030s story. The near-term unlock is 5G-Advanced plus edge compute. Design for that now; make 6G an upgrade, not a reset.
- “Cloud is always cheaper.” For steady inference with heavy egress or data gravity, on-prem clusters can beat cloud by double digits—after you cross a utilization threshold and modernize operations.
- “Standards will settle before we invest.” No-regrets investments exist today: power, cooling, colocation footprints, private cellular, data pipelines, and FinOps/ML governance.
- “Latency is just a technical metric.” Latency is a revenue variable. Sub-50 ms changes conversion in personalization; sub-10 ms enables new products (co-bots, remote inspection, AR-guided workflows).
Strategic Framework: The C.L.E.A.R. playbook
Use this to link TCO, ROI, and operating model across compute and networks.
- C — Calculate TCO inflection points
- On-prem AI supercomputers: include capex (nodes, switches, racks), facilities (power, cooling at 30–80 kW/rack), space, staffing, and software stack. Model 3–5 year depreciation and target 60%+ utilization.
- Cloud: include instance cost, storage, egress, and premium for burst elasticity. Don’t ignore data residency and compliance overhead.
- Breakeven heuristic: steady workloads with high egress and predictable SLAs often cross over to on-prem or colo in 9–18 months—if utilization and pipelines are mature.
- L — Locate latency and data gravity
- Map each workload by sensitivity: training (throughput), fine-tuning (data proximity), inference (p95 latency), and compliance (residency).
- Design a three-tier fabric: core DC/cloud, regional edge (colo with GPUs), and on-prem edge (factory, store, hospital) connected via private cellular now; 6G-ready later.
- E — Engineer for efficiency and reliability
- Adopt liquid cooling where density demands it; negotiate green PPAs or grid agreements to stabilize energy costs.
- Instrument everything: GPU utilization, queue times, model quality, and per-request cost. If you can’t see it, you can’t optimize it.
- A — Accelerate with the right operating model
- Stand up a “ModelOps + NetOps” fusion team: MLOps, SRE, network engineering, and security working from shared SLOs.
- Governance: model provenance, data lineage, and AI risk controls tied to release management. Treat models like products.
- R — Roadmap for 6G without waiting
- Deploy private 5G/5G-Advanced at critical sites; design radios, cabling, and spectrum plans with 6G upgrade paths in mind.
- Run pathfinder pilots: joint comms-and-sensing, non-terrestrial network integration, and time-sensitive networking for robotics.
TCO and ROI: What the board will ask
- Capex profile (AI supercomputers): front-loaded spend with 3–5 year depreciation. ROI typically hinges on:
- Cloud spend offset (egress avoidance, instance rightsizing),
- Cycle-time compression (faster experimentation to release),
- New revenue from latency-sensitive products.
- OpEx impacts: power costs, facility upgrades, premium support, and talent. Many leaders underestimate facility readiness by 20–30% in initial plans.
- Realistic timelines:
- On-prem GPUs: 3–9 months to install; 6–12 months to reach efficient utilization; early ROI can appear inside 12 months if workloads are ready.
- 6G: expect strategic ROI, not immediate payback. Use 5G-Advanced now; treat 6G as a multiplier for pilots that prove business value.
- Change management: reskill infrastructure teams to manage AI stacks; integrate FinOps with MLOps to enforce cost guardrails; align security with model and data governance.
What’s uniquely overlooked: facilities, firmware, and footprint
Most plans obsess over model choice and GPU counts. The quiet differentiators are:
- Facilities readiness: power density, liquid cooling, floor loading, and fire suppression drive time-to-value. Those who pre-book colo capacity win the calendar.
- Firmware and drivers: consistent, automated updates across GPU nodes and NICs prevent silent performance regressions that erode ROI.
- Footprint strategy: regional GPU edges near your largest data pools (and customers) reduce both egress and latency—often the fastest payback.
Action Steps: What to do Monday morning
- Baseline spend: build a 12-month view of AI-related cloud costs (compute, storage, egress) and model it against a right-sized on-prem cluster.
- Identify three anchor workloads for on-prem/edge (e.g., RAG over proprietary data, computer vision in operations, high-volume personalization) with clear SLOs.
- Stand up a GPU utilization dashboard and set a 70% target for steady-state workloads before expanding hardware.
- Secure power and space: pre-negotiate colo capacity and energy contracts; plan for 30–80 kW/rack and liquid cooling where needed.
- Deploy private 5G now at one flagship site; define a “6G-ready” blueprint so radios and backhaul upgrade without ripping and replacing.
- Create a fusion squad (ModelOps + NetOps + SecOps) with shared latency and cost SLOs; give them product owners and quarterly OKRs.
- Pilot two 6G-era capabilities today: joint comms-and-sensing for safety/automation, and non-terrestrial links for continuity in remote sites.
- Negotiate vendor roadmaps: lock firmware/cuda/network driver baselines; secure upgrade paths to Blackwell-era systems without full revalidation.
- Institute AI FinOps: tag every model and inference endpoint with unit cost; set guardrails for cloud vs on-prem routing based on price/perf.
- Launch a skills sprint: MLOps, RF fundamentals for network teams, and safety/regulatory training for model deployment.
Bottom Line
The next decade of competitive advantage will be won by companies that treat compute and connectivity as a single design problem. Use cloud for what it does best, stand up AI supercomputers where data and latency demand it, and evolve your networks now so 6G is an upgrade—not a reinvention. Move early on facilities, talent, and edge footprints, and you won’t just lower cost—you’ll ship products your rivals can’t.
Leave a Reply